
今回は生成AIに関連する著作権法上の問題について検討する。
まず、生成AIとは、知的財産戦略本部構想委員会(第2回)資料によれば、「コンテンツやモノについてデータから学習し、それを使用して創造的かつ現実的な、まったく新しいアウトプットを生み出す機械学習手法」であるとされている。
現在提供されている生成AIの典型例としては、ChatGPTやCopilotが挙げられる。
生成AIの構築にあたっては、AI開発者が著作物を含むデータを収集・複製し、モデルに入力して学習させる。
著作権法における著作物等の定義については後述するが、論文や記事(単なる事実の記載を除く)、イラストを含む美術作品、動画、音楽などはすべて著作物に該当する。
例えば、著作物を無断で複製することは著作者の権利侵害となる。したがって生成AIの学習にあたって、学習過程における著作物の複製・入力が違法となるかが問題となる。
また、生成AIにプロンプト(指示・質問)を入力することでテキストや画像などが生成される。生成されたテキスト・画像が既存の著作物の権利を侵害していないかどうかが問題となる。
ここには二つの問題があり、ひとつは利用者が特定の作品を複製することを意図したプロンプト(指令)を入力して、結果として特定の作品によく似た結果が出力されるケースが問題となる。
もうひとつは、これに付随して、利用者がそのようなプロンプトを入力していないにもかかわらず、生成AIが学習データと同一または類似した内容を出力する場合も問題となる。
以下では、文化審議会著作権分科会法制度小委員会の「AIと著作権に関する考え方」(以下、「考え方」)を基礎資料として検討を行う。これは判例の蓄積がない中で生成AIに関する著作権の考え方を示すことを目的にまとめられた報告書である。
生成AIの学習の仕組み
生成AIと著作権の関係を論じるにあたり、まず生成AIの基本的な仕組みを確認する。
生成AIには、主に開発者、サービス提供者(以下「提供者」)、および利用者という三つの主体が関与する。本稿では議論を明確化するため、提供者と開発者を同一主体として扱う。
生成AIの学習から出力に至る一般的なプロセスは、以下のとおりである。
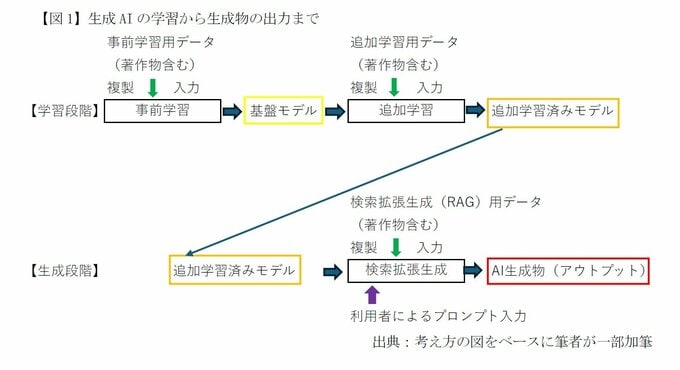
(ステップ1)まず、生成AIを構築するために、開発者が著作物を含む事前学習用のデータをモデルに読み込ませる。この工程により、生成AIの基盤となる学習済みモデルが構築される。
(ステップ2)次に、開発者は基盤モデルに対し、生成AIの用途(例:画像生成に特化したモデル)に応じた追加学習用データを読み込ませる。これによりシステムとしての生成AIは完成することとなる(追加学習済みモデル)。
(ステップ3)利用者が生成AIから生成物を出力させるためのプロンプトを入力する。この工程では、AIがプロンプトに基づき関連情報を検索し、必要に応じてデータベースを参照する。これは後述する検索拡張生成(RAG)技術を利用するものである。
(ステップ4)最後に、生成AIが生成結果を提示する。
著作権法
1|総論
著作権法は、著作物の公正な利用を確保しつつ、著作者(著作物の創作者)の権利を保護することを目的としている(著作権法1条)。すなわち、著作物の利用促進と著作者の権利保護の両立を図る法律である。
著作者が有する著作権は、知的財産権の一種である。知的財産権とは、形を持たない無体物に関する権利を定めるものである。例えば、絵画の著作権は、有体物としての絵画そのものの所有権とは独立し、絵画の表現という無体物に対して認められる。
著作権法は著作物を「思想又は感情を創作的に表現したものであって、文芸、学術、美術又は音楽の範囲に属するもの」と定義している(同法2条1項1号)。そのため、以下のようなものは著作物として保護されない。
・思想や感情を含まない単なる事実やデータ
・創作性のない、ありふれた表現
・アイデアにとどまり、表現として具体化されていないもの
・文芸・学術・美術・音楽の範囲に属さない実用品など
著作物の具体例は上述した。
2|著作者の権利および権利制限
ただし、著作権法は、著作物を利用するすべての行為に著作者の権利が及ぶと定めているわけではない。例えば、論文を読む、絵画を鑑賞するなどの行為そのものには著作権は及ばない。著作権が及ぶのは、法が規定する特定の利用行為に限られる。
具体的に生成AIと関連する権利としては、(1)著作物を複製する権利(複製権、著作権法21条)、(2)公衆送信する権利(公衆送信権、著作権法23条)、(3)著作物を翻訳・編曲・変形等する権利(翻案権、著作権法27条)等がある。
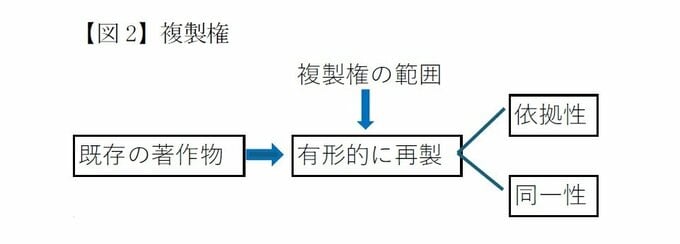
AIの学習・生成過程では、特に複製権が重要となる。複製権は「有形的に再製すること」と定義されている(著作権法2条1項15号)。「再製」とは、既存の著作物に「依拠」して、その表現上の「本質的特徴を直接感得しうるもの」を作成することをいう。
ここで依拠性とは既存の著作物の表現をもとにして制作したということであるが、一般に、依拠性とは、既存の著作物の表現を基にして制作したことを指す。
一般には、(1)生成物が既存の著作物と高度に類似していること(同一性)、および(2)作成者が当該著作物にアクセス可能であったこと、という二点から判断される。
したがって、生成物が既存の著作物と同一性を有すると認定されれば、その表現の本質的特徴を直接感得できるものと評価される。
次に、依拠性の判断として、作成者が既存著作物にアクセス可能であったかが検討され、この二点によって複製権侵害の有無が判断されてきた。
絵画をコピー機で複製する行為は複製権の侵害となる。また、手書きであっても、オリジナルと極めて類似した作品を作成した場合も複製権侵害が成立し得る。
AI学習の場合、デジタル形式の著作物を収集し、モデルに取り込む一連の工程が複製に該当する。
これらの権利を行使するには著作者の許諾が必要となるが、許諾を要せずに利用できる場合が著作権法に規定されている。これらの規定は著作者の権利を制限するものであるため、権利制限という。
権利制限の典型的な場合として、私的利用のための複製がある(著作権法30条)。例えば、図書館から借りてきた本の文章を、個人で私用のため書き写すような行為(複製行為)には著作者の権利が及ばない。
そして次項で取り上げるのが、生成AIをはじめとする学習用データの利用に大きく関連する権利制限である。
3|生成AIに関連する著作権法の規定
関連する条文は以下の2条である。
(1) 非享受目的規定
まず、AI学習と特に関連する規定として、著作権法30条の4(いわゆる非享受目的規定)が挙げられる。同条は、著作物に表現された思想や感情を「享受する目的」がない場合には、必要と認められる限度で利用を認めるというものである。
これは、著作物の本来的な目的である「享受」(内容を鑑賞すること)を伴わない利用は、一般に著作者の利益を害しにくい。このため、同条は「高度に柔軟な権利制限規定」として導入された。
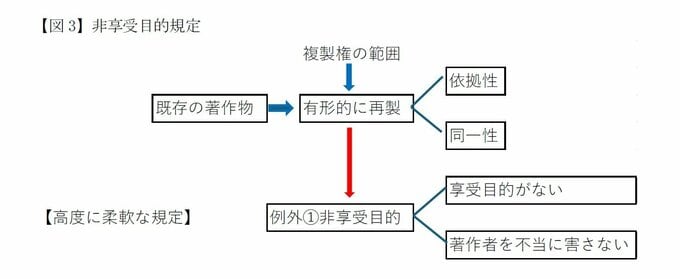
典型的なケースとして「情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう)の用に供する場合」が挙げられている(同条2号)。
すなわち、情報をデータとしてデータベースに読み込み、解析のために活用する場合は著作者の権利が及ばない(権利制限)。
ただし、著作物の種類及び用途並びに利用の態様に照らし著作者の利益を不当に害することとなる場合には権利制限が否定される(=著作権法違反である。同条但し書き)。
(2) 軽微利用
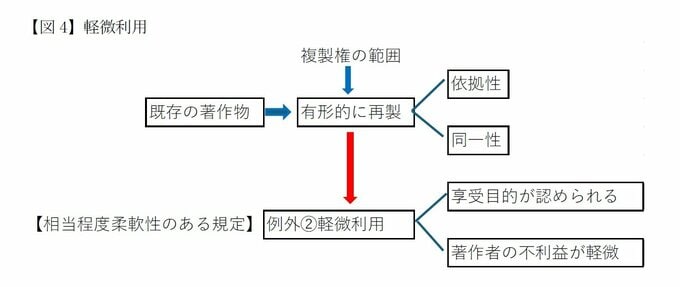
次に、著作権法47条の5(軽微利用)である。同条は、公衆に提供された著作物にあっては、電子計算機を用いた情報処理により新たな知見又は情報を創出することによって著作物の利用の促進に資する場合において、著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なものに限っては、利用できるとする(軽微利用)。
著作物の利用の促進に資する場合として、電子計算機を用いて、(1)検索により求める情報を検索し、その結果を提供すること(同条1項1号。検索結果として新聞記事の一部をスニペット表示するなど)、および(2)情報解析を行い、及びその結果を提供すること(同条1項2号)が挙げられている。
2号はAI学習とも関係が深い。情報解析の過程で享受目的が含まれる場合でも、著作者の利益が軽微にとどまると判断されれば利用を認めるものであり、「相当程度柔軟性のある規定」として設けられた。
また、これらの規定において「柔軟性」という概念が用いられているのは、米国著作権法107条のフェアユース規定の影響を受けたものとされる。
米国では、著作物を著作者の許諾なしに利用できる根拠として抽象的な規定であるフェアユースの考え方を採用している。フェアユース規定により公正な利用に該当すると判断される場合には、具体的なケースに応じて裁判により解釈を示してきた歴史がある。
日本では従来、権利制限規定は個別的・限定的であった。しかし、IT社会の進展を背景に、法改正により抽象度の高い柔軟な権利制限規定が導入された。
開発者の開発・学習行為と著作権法
1|基盤モデル構築のための事前学習
AIモデルの事前学習におけるデータの入力・複製が著作権法上合法かどうかは、非享受目的規定(30条の4)の適用が鍵となる。
学習用データとは、生データを欠測値や外れ値の除去、タグ付け(アノテーション)などの加工を施し、構築されたデータ集合をいう。
事前学習に関するこれらデータの複製・入力については、大量の情報から当該情報の要素に係る情報を抽出して解析を行うものであることから「情報解析の用に供する」行為にかかるものと考えられる。
そして、人による享受目的がないことから、非享受目的利用として著作権法30条の4第2項に該当し、原則として著作権侵害には当たらない。
また、基盤モデルに入力された事前学習データは、最終的に数値パラメータとして抽象化されるにとどまる。そのため、元の著作物の創作的表現がモデル内部に保持されることは通常ないとされる。
したがって考え方でも、事前学習済みのAIモデル自体には「学習に用いられた著作物の複製物とはいえない場合が多いと考えられ(る)」とされている。
2|生成AIモデル構築のための追加学習
追加学習データの複製・入力についても、事前学習と同様に非享受目的規定の範囲内と解され、原則として著作権侵害には該当しない。
ただし、「考え方」では、学習済みモデルに対し小規模なデータセットを用いた追加学習を行うことで、当該データセットの影響が強く反映された生成物を出力できる技術が存在する点を指摘している。
すなわち、追加学習は生成物の出力に直接影響を与えるために行われるステップであることから、生成物に学習データに存在する既存の著作物の複製を出力することが技術的に可能であるとする。
そして、「考え方」では、追加学習が特定の著作物の創作的表現を直接感得できる生成物の出力を目的としていると評価される場合には、享受目的があるため、30条の4の非享受目的規定は適用されないと整理している。つまり、この場合は複製権侵害の可能性がある。
しかし、開発者が享受目的を有していたかどうかを、著作者側が立証することは困難である。この点、考え方でも、単にAIが学習した著作物と創作的表現が共通した生成物が生成される事例があっただけでは、開発・学習段階における享受目的を推認することはできないとしている。
例えば、特定の既存画像を再現できることを宣伝文句として提供している場合を除けば、開発者が享受目的で追加学習を行ったと立証する事例は多くないと考えられる。
さらに、「享受」目的がある場合には著作権法47条の5の「軽微利用」が問題となる。
同条の適用にあたっては、出力された生成物における創造的表現が「著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なもの」にとどまるときは、軽微利用として複製権を侵害しない。
したがって、既存の著作物の表現が生成物に付随的に表れているということにとどまるのであれば同条の権利制限の範囲内と思われる。
他方、開発者が既存の著作物の複製となる生成物の出力を目的と評価されるに至るような場合には、「軽微利用」とはいいがたく、同条においても権利制限にはならないと考えられる。
3|作風
追加学習において、特定のクリエイターの少量の著作物を学習データとして読み込ませることで当該作品群の影響を強く受けた生成物の生成を可能にすることが行われており、その結果、当該クリエイターの作風を模倣した生成物が出力される可能性がある点への懸念が示されている。
例えば「漫画家〇〇風」や「イラストレーター△△風」などの画像が考えられるが、このように、作風の類似は原則としてアイデアの範疇にとどまり、作風が共通するだけでは著作権侵害には該当しない。
上述の通り、著作権法は表現を保護する法律であり、そのもととなるアイデアについては保護が及ばないためである。
もっとも、作風と具体的な表現の境界は明確ではなく、既存の著作物の創作的表現が直接感得できる場合には、著作権侵害に該当する恐れがあると考え方では述べられている。
また、考え方では、このような場合に至らなくても、アイデアや作風を模倣した出力をするAIについて、生成行為が営業上の利益や人格的利益を侵害する場合に不法行為に該当する可能性があるとしている。
4|検索拡張生成(RAG)
利用者がプロンプトを入力した際に、当該プロンプトに基づいて既存のデータベースやインターネット上のデータに含まれる著作物の内容をベクトルに変換(=コンピュータが読み取れるデジタル形式に変換)してデータベースを作成し、これを参照しつつ回答を生成する技術があり、これを検索拡張生成(Retrieval-Augmented Generation、以下、「RAG」)という。
RAGは生成AIの回答出力にあたって、学習データ以外の信頼できるデータを参照することで、ハルシネーション(幻想)を防止すること等に役立つ。
RAGにおける検索結果の複製は、AIモデルによる情報参照を目的とするものであり、享受を伴わない。このため、非享受目的規定が適用され、原則として著作権侵害には当たらない。
他方、上記の追加学習で述べたところと同様に、「学習データの著作物の創作的表現を直接感得できる生成物を出力することが目的と評価される場合」には、「享受目的」があるため、著作権法に違反することとなる。ただ、このような場合は追加学習で述べたところと同様に判断される。
そしてRAGでは、直近のインターネット検索を行うことから、特にロングテール・クエリ(めったにない質問)に関するプロンプトが入力された場合には、多くの検索結果が存在しないことがあり、検索結果の著作物が生成物に近い形で出力されてしまう可能性がある。
ただ、このようなケースは偶々生ずることはあっても、それが「享受目的」と評価されることは多くはないものと考えられる。
仮に「享受目的」と評価されるような場合には、軽微利用にかかる著作権法47条の5の適用の有無が問題となる。
この点は上述で述べた通りであるが、プロンプトに応じて偶々それだけが出力されたものと言えるにとどまるのであれば、同条権利制限の範囲内である(権利侵害はない)と考えられる。
開発者の開発・学習行為と著作者の利益を不当に害する場合
1|総論
著作権法第30条の4の但し書きでは「当該著作物の種類及び用途並びに当該利用の態様に照らし著作者の利益を不当に害することとなる場合は、この限りでない」と規定しており、同条2号にある技術解析目的の利用であっても、但し書きに該当する場合には権利制限されない。
考え方では、同条但し書きに該当するかどうかを検討するに当たっては、著作者の著作物の利用市場と衝突するか、あるいは将来における著作物の潜在的販路を阻害するかという観点から、技術の進展や、著作物の利用態様の変化といった諸般の事情を総合的に考慮して検討することが必要と考えられると指摘する。
そして、このような観点から、考え方では、学習データとしてデータベースの著作物と海賊版の複製・入力について検討している。
2|データベースの著作物
情報の選択または体系的な構成によって創作性を有するデータベースは「データベースの著作物」として著作権法上保護される(12条の2第1項)。すなわちデータの組み合わせであって、データの配列や選択に独創性があれば著作物性が認められる。
また、個々のデータが取材記事(単なる事実の記載にとどまらない記事)であるなどデータそのものが著作物である場合も考えうる(新聞社サイトや日経テレコムなど)。この場合は、データそのものの著作権とデータベースの著作権が重複的に存在することとなる。
このような創作的表現が認められる一定の情報のまとまり(データベース)を情報解析目的で複製する行為は、30条の4の但し書きに該当し、著作権法に違反する場合があり得るものと考え方では整理している。
特に、有料で販売されているデータベースの個々のデータを、生成AIの学習データとして利用する場合について問題となるが、それについては次項で述べる。
3|著作者による複製防止技術の適用
新聞社などでは自社の記事のインターネット上のファイルに「robots.txt」を記述することで、検索のためのインデックス化(学習データとしての読み込みも含む)を拒否する指示を書き込むことを行っている。
そして有償のAPI(Application Programming Interface。システム同士を連結する方法のこと)連動でデータを提供しているケースがある。また、ファイルにパスワードが付しており、一般にはアクセスできない状態に置かれているものがある。
そもそも、著作権法30条の4は著作者の利益を害しない場合であれば、著作者の意思とはかかわりなくAI学習を可能にするものである。
考え方では、著作者によるアクセス制限は著作権法30条の4の効力を否定するものではなく、AI学習のためのデータ取得・複製の合法性に関して影響を与えないとしている。
ただし、データベースを現在提供しており、あるいはアクセス制限措置が講じられていることや過去の実績などから将来的にデータベースとして販売される予定であると推認される場合においては、AI学習が将来の潜在的販路を阻害する行為として法30条の4の但し書きに該当する(=著作権法に反する)としている。
これは著作物であるデータベースの利用市場の機会を、生成AIが奪取する場面での問題である。
この点、新聞社の公開している記事群はそもそも既存のデータベースの一部であり、検索結果に従い記事を表示しているだけとの指摘がある。
そうすると、例えばAPI連動を行わず、ポータルサイト経由で無料記事を取得することはデータベースの一部を複製している。
このことは著作権法30条の4但し書きに該当し、著作権法違反となるものと考えられる。また、この場合、著作権法47条の5でも権利制限の例外となる「当該軽微利用の態様に照らし著作者の利益を不当に害する」にも該当し、著作権法違反となる。
4|海賊版等の複製
AIの事前学習・追加学習において海賊版を複製・入力する可能性がある。海賊版をそれと知りながら排除する措置を取らなかったということを回避すべきというのは当然である。
過失の場合に関しては、考え方では、海賊版等の権利侵害複製物を掲載するウェブサイトからの学習データの収集を行う場合等において、問題となるのは事業者において以下に当てはまる場合とする。
すなわち、
(1)少量の学習データに含まれる著作物の創作的表現の影響を強く受けた生成物が出力されるような追加的な学習を行う目的を有していたと評価され、
(2)当該生成AIによる著作権侵害の結果発生の蓋然性を認識しながら、かつ、
(3)当該結果を回避する措置を講じることが可能であるにもかかわらずこれを講じなかったといえる場合である。
この場合は、当該事業者は著作権侵害の結果発生を回避すべき注意義務を怠ったものとして、当該生成AIにより生じる著作権侵害について規範的な行為主体として侵害の責任を問われる可能性が高まるものと考えられるとする。
侵害行為に対する措置
1|総論
侵害の有無が問題となるのは、一般に、生成物と既存の著作物との同一性が認められる場合である。生成物が出力・公表されることで、著作者は自身の著作物が複製されたものと認識でき、著作権侵害を主張できることとなる。
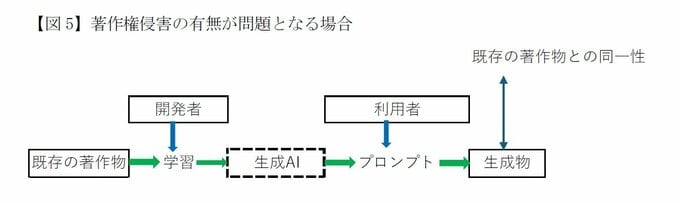
考え方で示されている中で、既存の著作物と生成物の表現の同一性が問題とならない唯一の例外としては、開発者がデータベースのデータを読み込むことが著作権侵害になる場合である。
この場合においては、著作物であるデータベースの著作者の権利を不当に害するものとして、著作権法30条4の権利制限の適用がなく、学習データを読み込むことが開発者による著作者の複製権の侵害となる。
2|差止請求
著作者はAI学習、あるいは利用に際して著作権侵害が生じた場合、AI学習のための複製を行った開発者あるいは生成物を出力した利用者に対し、侵害行為の差止請求(侵害行為の停止又は予防の請求(著作権法112条1項)及び侵害の停止又は予防に必要な措置の請求(同条2項))を行うことが考えられる。
差止請求を行う者は(1)自身が著作権を有すること、および(2)開発者が著作権を侵害したことを主張立証する必要がある。
ここで論点となるのは、(2)の著作権侵害があったかどうかである。生成物が既存の著作物に依拠性があり、かつ同一性があることで侵害の有無が判断される。
すなわち、既存の著作物との同一性があり、かつ既存の著作物に基づいている(アクセスがある)とされる場合である。
3|損害賠償請求
損害賠償請求は不法行為に関する規定である民法709条に基づいて行われる。損害賠償請求においては上記2|の(1)(2)に加え、(3)被告の故意または過失、および④被告の行為による損害の発生を立証することが要件とされている。
責任の主体は誰になるかという問題については次項以降で述べるが、責任主体に故意・過失があるかが損害賠償請求において特に問題となる。
4|利用者が責任主体となる場合
著作権を侵害する生成物が出力された場合においては、物理的な侵害行為を行った主体が法的責任を負う。
この判断にあたっては、複製の対象、方法、複製への関与の内容、程度等の諸要素を考慮して、誰が当該著作物の複製をしているといえるかを判断すべきである(最判平成23年1月20日「ロクラクII事件判決」)とされている。
利用者が一定のプロンプトを入力した結果作品が生成されることを考慮すると、AI開発者・提供者が実際に主体といえるような事案は必ずしも多くないとの指摘がある。
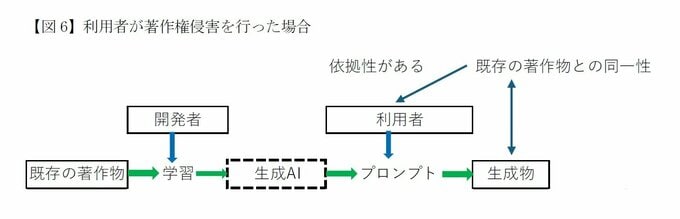
典型的な例としては、プロンプトとして利用者が特定の著作物を読み込ませ、これに類似する生成物を出力するケースである(Image to Image)。この場合は、依拠性が明らかであり、かつ同一性も認められることから著作権侵害が認められる。
同様の例としては、具体的な既存の著作物を利用者がイメージしながらプロンプトを入力することにより、これに類似した生成物が出力したケースも考えられる。
なお、作品に同一性があることは客観的に判断されるが、依拠性は利用者が既存の著作物にアクセス可能であったかどうかで最終的に判断されるので、その立証には困難が想定される。
問題となるのは、利用者が生成物の出力にあたり、同一性が認められる既存の著作物を認識していなかったが、生成AIが学習データとして読み込んでいた場合である。この場合に、既存の著作物と類似性のある生成物が出力されたケースが生じうる。
この場合にも、考え方では、利用者について依拠性が認められるとする。ただし、この場合においては、利用者に通常は故意・過失がないので、差止請求(生成物の掲示やネットでの公開の停止など)のみが認められ、損害賠償請求については、認められないということになる。
5|規範的行為主体論
裁判例では、著作権侵害の主体として、物理的に侵害行為を行った者が主体となる場合のほか、一定の場合に、物理的な行為主体以外の者が、規範的な行為主体(あるべき論としての責任者)として著作権侵害の責任を負う場合がある(いわゆる規範的行為主体論)としている。
AI生成物の生成・利用が著作権侵害となる場合の侵害の主体の判断においては、物理的な行為主体である当該AI利用者が著作権侵害行為の主体として、著作権侵害の責任を負うのが原則である。
他方で、上記の規範的行為主体論に基づいて、生成AIの利用者ではなく、開発者・提供者が、著作権侵害の行為主体として責任を負う場合があると考えられる(学習データの読み込みがデータベースの著作者の権利を不当に害する場合は上述の通り)。
AI開発者・提供者が、もっぱら特定の著作物の侵害のみを目的とする生成AIを作成し、他人の使用を意図して提供した場合は、他人の使用により、著作権の侵害を惹起したものとして不法行為に基づく損害賠償責任を負う(最判平成13年2月13日「ときめきメモリアル事件判決」を参考)。
また、侵害の主体とまではいえなくても、著作権侵害を惹起する生成AIを提供した事業者が、一定の場合に利用者のほう助者として責任を負う場合もある(最判平成13年3月2日「ビデオメイツ事件判決」を参考)。
考え方では、例えば「ある特定の生成AIを用いた場合、侵害物が高頻度で生成される場合は、事業者が侵害主体と評価される可能性が高まるものと考えられる」とする。
したがって、このような結果が想定されるのであれば、防止措置を講ずることが法的責任を回避するために必要となる。
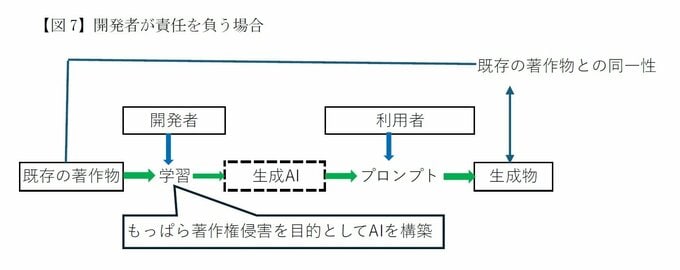
これらの事情が認められる場合において、考え方では、著作権侵害の対象となった当該著作物が、将来においてAI学習に用いられることに伴って、複製等の侵害行為が新たに生じる蓋然性が高いといえる場合は、当該 AI 学習に用いられる学習用データセットからの当該著作物の除去が、将来の侵害行為の予防に必要な措置の請求として認められ得るとする。
他方、考え方では「AI学習により作成された学習済モデルは、学習に用いられた著作物の複製物とはいえない場合が多いと考えられ、「侵害の行為を組成した物」又は「侵害の行為によって作成された物」には該当しないと考えられる」といった理由等から通常、廃棄請求は認められないとする。
生成物の著作物性
生成AIで作成した生成物に著作権は認められるかという問題がある。昨今、ネット上で流布されているAI作成のキャラクター画像が、相互に似たようなものがしばしば見受けられる。生成AIにより出力した生成物について著作権を主張できるのであろうか。
まず、生成AI自身が著作者となるかどうかについて、著作権法は著作者が「著作物を創作する者」(著作権法2条1項2号)とされていることから、文理解釈により人に限られる。したがって生成AIが著作者にはならない。
次の問題として、生成物を出力させた利用者が著作者となるのかという問題がある。この点、文化庁「著作権審議会第9小委員会(コンピュータ創作物関係)報告書」第3章―I-1によれば「コンピュータ創作物についても、人が思想感情を創作的に表現するための『道具』としてコンピュータ・システムを使用したものと認められれば、その著作物性は肯定されることになる」とする。
そして、コンピュータを道具にしたといえるためには、人による「創作意図」と創作過程において具体的な結果を得るための「創作的寄与」があれば、著作物性が認められるとする。
米国ではAIの生成した生成物について職務著作を主張して自らの著作権を主張した事件がある(ターラー事件)。
同判決の説くところによれば、人の作品への関与、および最終的な創作についてのコントロールが新しいタイプの作品が著作権の範囲に含まれるという結論に重要であるところ、コンピュータが自律的に作成した作品にはそのようなコントロールはなく、したがって著作権は生じないとした。
また、米国では著作権登録という制度があり、AIを利用して出力した生成物について自身の著作権を主張した事例がいくつかある。
このなかでも生成物に35回もの加工を施したものについて著作権が認められたものがある(A Single Piece of American Cheese事件)。米国では生成物出力までに工夫したというだけでは著作権性を認めることに否定的である。
日本においては、「プロンプトを駆使したり、類似度を指定したりして、繰り返しランダムに画像を生成させ、そのなかからよいものを一つ『選択』する行為は編集著作物の創作性を基礎づける『選択』にあたるのではないか」との主張がある一方、「現行著作権法上、自然物をひとつ選択しただけでは、表現としてはあくまで自然物であることに変わりなく、表現が創作されたとはいいがたい(したがって生成物の中から一つ選択したからと言って表現が創作されたわけではない)」との主張もある。
後者の立場に立てば、生成物を出力するまでの工夫は創作的寄与とはならず、出力された生成物にさらに一定以上の人の手を加えることで創作物として認められるということになり、米国の事例と整合的である。
検討
本文で述べたところを整理し、コメントを付すと以下の通りである。
(1) 生成AIモデルへの著作物の読み込み(原則)
開発者が著作物を含むAI学習データを収集し、そのうえで複製・入力するのは著作権法30条の4に基づき原則として合法である。
学習データの収集は、権利者から個別契約で取得する場合のほか、ネット上から取得することが考えられる。
ネットからの取得について、個別契約に基づいていれば著作権の許諾を得ることもできるものの、ネット上から自動収集する場合は、著作権の許諾の有無の区別は事実として前提とならない。
このようなことから著作権法30条の4は、著作物本来の効用である「享受」目的のない著作物のシステムへの読み込みにあたっての高度に柔軟な規定として、著作権法の権利制限規定として設けられている。
これはAI技術の促進寄与にかなうものであり、著作権法上の目的である公正な利用に該当するものである。すなわち冒頭で書いた主要論点①は原則として合法ということになる。
著作物であってもそれを著作物として利用しないのであれば、著作者の権利を侵害しないと理解することになる。また、このルールには著作者の権利を不当に害さない場合という例外規定もあり、利用促進と権利保護のバランスも同条では取りやすいといえる。
また、「享受」目的があるとしても利用者の不利益が軽微といえる場合には著作権法47条の5により権利制限され、著作物の利用は合法である。
(2) アクセス制限されているデータ
上記で述べたことはネット上でファイルにパスワードが付されており、会員登録をしなければ閲覧できないコンテンツであっても同様に当てはまる。
ここで、パスワードが付されているコンテンツそのものは、通常は自動収集の対象外になるものと思われる。
しかし、例えば新聞社の有料記事がポータルサイトで無料公開され、あるいは他者に無断転載されており、それらを学習データとして取り込んだとしても一般に著作権侵害とはならない。
特に無断転載の場合における、このような結論は一見すると理解しづらい。しかし著作物を「享受」しない使い方、すなわち著作物を著作物として利用しないため導かれる結論はこのようになる。
この点、考え方でも海賊版と知って取り込んだような場合でなければ権利侵害を問われないと整理している。
しかし、米国の事例では、生成AIにより出力された画像に元画像の「透かし」が現れているものがあり、そのことをAIモデルへの複製・入力で不正な入力があったと主張されたものがある。
日本においては、このような場合であって、既存の画像がデータベースの一部を構成するものである場合には、画像データの読み込み自体が著作者の権利を不当に害するものとして著作権を侵害すると判断され、差止請求または損害賠償の対象となるものと考えられる。
またこの場合、利用者が既存の著作物の「本質的特徴を直接感得しうる」生成物を出力した場合には差止請求の対象となる。
(3) 作風
作風には原則として著作権法の保護が及ばない。これも一見して理解しづらい。生成AIによる作風の模倣は、既存の著作物の特徴を活かしているのではないかとの疑問があるからである。
しかし、これも著作権法30条の4によれば「当該著作物」の表現を「享受することを目的としない場合」に該当し、原則として合法となる。
例えば印象派の画家は一見して印象派とわかる作品を制作しているが、各々の著作権はそれと関係なく成立するといったものに類するであろう。ただし、作風というにとどまらず「当該著作物」の「本質的特徴を感得しうるもの」になるような場合は著作権侵害の可能性が出てくる。
印象派というだけにとどまらず「モネの睡蓮の絵」という程度に至るものは、当該著作物を複製したものとして違法になる可能性があると考えられる。
(4) データベースとしての販売
上記(1)~(3)の通り、開発者が生成AIにより著作権を侵害することを目的としない限りにおいては、原則として制限なしに著作物をAIモデル学習のために利用できる。
他方、「robots.txt」をはじめとするアクセス制限措置をとることを含め、現在あるいは将来的に「データベースの著作物が販売され、あるいは販売予定であると推認される場合」には「著作者の利益を不当に害する」ことから著作権法30条の4但し書きに該当し、著作権法違反となる。
これは既存の著作物であるデータベースに対して、データベースと同等に機能しうる生成AIが直接侵害するものになるからである。
AI開発者にとっては、「robots.txt」を記載するファイルの所有者がデータベースを販売しているか直ちにわかるわけではない。ましてや「将来的に販売予定」といった将来予測までAI開発者が判断することは困難である。
他方、「robots.txt」が記載されているファイルは一切収集してはならないとした場合には、ニュースサイトをはじめ媒体社側が幅広く記載をする恐れがあり、その場合、AI学習に支障をきたすのではないかとの懸念もある。
考え方は中庸を取っているわけではあるが、実務的に支障をきたさないかは今後の展開を見る必要がある。
(5) 利用者による侵害
上記(1)~(4)は開発者による既存の著作物のAIモデル構築にあたっての利用が著作権法違反となるかどうかの問題であった。
これらは開発者が既存の著作物の著作権侵害を目的とする場合、データベースの販売で利益衝突が発生する場合を除き、著作権法に違反しないとされている。
他方、利用者は生成物を出力するプロンプトを入力するため、著作物を侵害するような内容のプロンプトである場合には、著作権法違反となることは理解しやすい。
しかし、さらに利用者が意図せずとも生成AIの学習データとして読み込まれており、偶然に著作権を侵害する生成物が出力された場合(AIによる依拠)においても利用者が権利侵害を行ったと考えられていることは一見理解しづらい。
この点は、著作権侵害行為が発生した以上、誰かを行為主体として把握しなければ差止請求ができないという法技術的な面が存在するものと考える。
この場合は利用者に故意・過失がなく、損害賠償請求は認められない。意図的に著作権侵害を行った場合のほか、生成AIの学習データとして取り込んでいた場合も著作権法上問題となるというものである。
なお、AIによる依拠は著作者が立証するのはむずかしい。上述(2)のように透かしが映り込んでいるようなケースなどに限られた事例にとどまるものと思われる。
おわりに
開発者がAIモデルへの学習データの読み込みを行うにあたって、著作権を侵害するとされるケースは多くない。これはAI技術の進展に著作物の利用が不可欠であるからだ。
侵害となるのは故意に特定の生成物の出力を行おうとした場合のほか、他者のデータベース著作物を侵害するようなケースに限定される。
他方、利用者にはこのようなセーフハーバーが認められない。それは生成AIが道具のようなものだからだ。例えばパソコンの描画ソフトで有名な画像に似た作品を生成するのと変わらない。ただ、生成AIの出力は利用者が簡単にコントロールできるものではない。
上述の通り、米国では生成物へのコントロールが認められないため、著作物性が安易に認められないとしていることからも、そのことがうかがわれる。
したがって利用者が故意に特定の画像に似せた生成物を出力したような場合でなければ、通常は著作権侵害とはならないものと考えられる。
なお、本稿執筆中、生成AIで既存の著作物である画像を無断で複製したとして、千葉県警が神奈川県の男を著作権法違反(複製権侵害)の疑いで地検に書類送検する方針を固めたとの記事が出た。
同記事によると2万回以上のプロンプトを入力したということであり、また同事件を報道したニュース番組の映像を確認したところ、かなり複雑な絵柄をほぼトレースしたような生成物が出力されており、著作権侵害での刑事立件が可能と県警が判断したことは首肯できる。
比較的AI開発者・提供者・利用者に有利な法制度となっていると言えるが、悪意を有する利用者にも一定程度対応できるものと考えられる。
考え方は、判例の蓄積がない現状で学識者の知見を集積したものであるため、今後の判例の蓄積により、より一層実務的に支障をきたさない慣行が構築されていくことが期待される。
※情報提供、記事執筆:ニッセイ基礎研究所 保険研究部 研究理事 兼 ヘルスケアリサーチセンター長 松澤 登
※なお、記事内の「図表」と「注釈」に関わる文面は、掲載の都合上あらかじめ削除させていただいております。ご了承ください。















