映像を自然言語化する視覚言語モデル(VLM)を開発
自動運転技術とともに、交通事故ゼロを目指すためにWoven by Toyotaが独自に開発し、世界で注目を集めている技術が、今回初めて製品として公開された。「Woven City AI Vision Engine」と名付けられた、映像解析のためのマルチモーダル大規模基盤AIだ。
マルチモーダルとは、テキストや画像、動画、センサーのデータなど、複数の異なる種類のデータを統合して処理する技術のこと。このAIは街や施設に設置されたカメラ映像を解析して、映像の前後の文脈も含め瞬時に自然言語化する「視覚言語モデル(Vision Language Model=VLM)」と呼ばれるものだ。Woven by Toyotaが独自で開発した基盤AIであり、VLMとしては世界トップレベルの性能を誇っているという。
会場で、Woven City AI Vision Engineと繋がったカメラの前に立ってみた。すると、タブレットの画面に次の文章(実際は英文)が瞬時に現れた。
「コンベンションセンターや広いホールのような広い室内空間に人々が集まっています。そこは明るく、天井が高く、背景には工業的なスタイルの照明器具が見えます。人々はカジュアルな服装をしていて、ジャケットを着ている人もいれば、Tシャツ姿の人もいます。彼らは会話を楽しんだり、背景にある何かを観察したりしているようです。全体的な雰囲気はカジュアルでリラックスしていて、おそらく人々が交流している社交的な集まりやイベントのようです」

このように、映像で捉えた空間の全体像から、人々の服装やそれぞれの動き、それに雰囲気までも文章にしていた。開発マネージャーの小竿陽平さんは、このAIを使った自動運転の検証を、ウーブン・シティ内で行っていると明かす。

「車に搭載したドライブレコーダーなどのカメラでは、建物の影に隠れているものは検知できません。それが、ウーブン・シティには街のインフラに多数のカメラが設置されていますので、このカメラのデータとAIをつなげることで、建物の影に隠れた人がこの後道路に出てきて、横断歩道を渡ろうとすることなどがテキストで記述されます。この情報をもとに、AIが危険度を三段階に色分けして、車やドライバーに知らせる検証をしています」

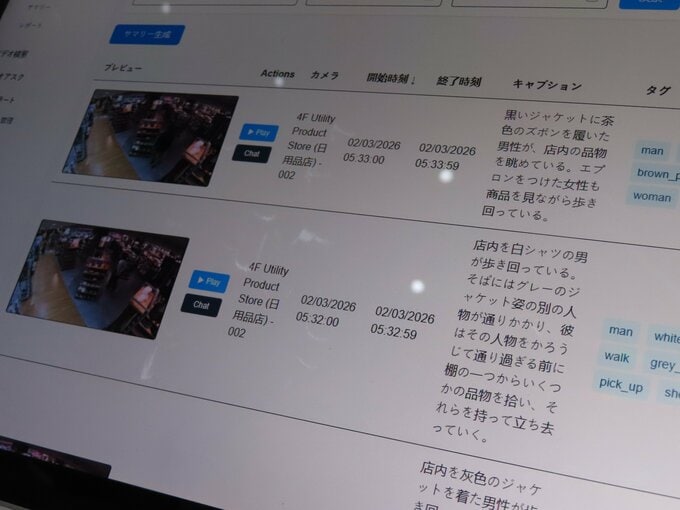
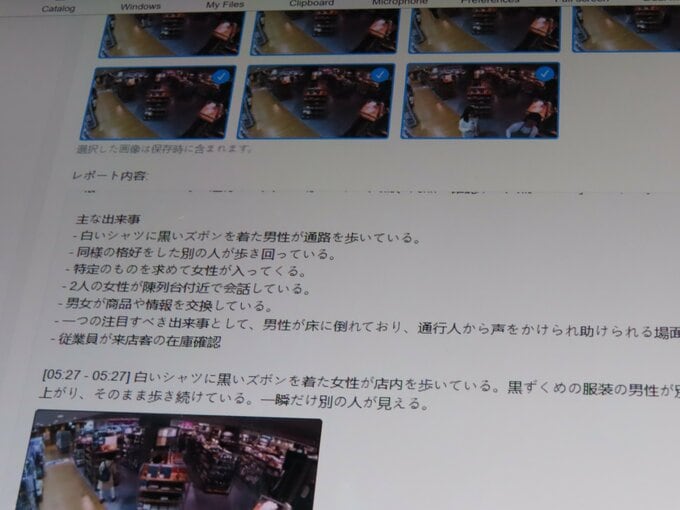
また、自然言語化するシステムは、自動運転だけでなく幅広い業界でも利用できる。小売店に導入された場合には、店内のカメラに映った映像から人の動きが細かく記述される。記述された一定時間内の主な出来事を、ChatGPTを使って瞬時にレポートとしてまとめることもできる。実際に警備や防犯、マーケティングなど、異業種への販売が始まっている。
会場ではこのほかにも、トヨタグループによるさまざまなAI技術が展示された。「Woven City Robot Platform」では、ロボットにスプーンなどをつかむ動作を覚えさせているところが公開されたほか、トヨタ自動車の豊田章男会長に代わって質問に答える「豊田章男AI」も登場した。


AIを活用することによって、人、モビリティ技術、インフラをデータで繋ぎ、交通事故のない社会を目指しているトヨタグループ。その技術を進化させているのは、ウーブン・シティと運営会社であるWoven by Toyotaが開発した最先端のAIであることが今回の取材で垣間見えた。
「調査情報デジタル」編集部
【調査情報デジタル】
1958年創刊のTBSの情報誌「調査情報」を引き継いだデジタル版のWebマガジン(TBSメディア総研発行)。テレビ、メディア等に関する多彩な論考と情報を掲載。原則、毎週土曜日午前中に2本程度の記事を公開・配信している。